
요약 (Summary)
'동네한끼' 프로젝트의 핵심 기능인 개인화 추천 API의 부하테스트를 진행하며
응답 속도가 평균 26초에 달하는 심각한 성능 저하를 확인했습니다.
이를 해결하기 위해 로직 수정, DB 커넥션 풀 조정, 쿼리 리팩토링, 인덱스 적용, JVM 튜닝의 4단계를 거쳤습니다.
그 결과, RPS는 증가(30.19→ 42.4)하고, 응답 속도는 단축(1656ms → 1100ms)하는 성과를 얻었습니다.
1. 배경 및 문제 상황 (Background & Problem)
프로젝트 리팩토링 과정에서 메인 페이지의 '사용자 맞춤 추천 게시글 조회 API'를 점검하던 중, 예상보다 훨씬 심각한 성능 지연을 발견했습니다.
해당 API는 로그인한 사용자의 활동(좋아요, 조회 등)을 분석해 관심사를 파악하고, 이에 맞는 게시글을 추천하는 복합적인 로직을 가지고 있습니다.

1-1. 로직 흐름
- User Context: 현재 접속한 사용자가 좋아요를 누른 게시글 목록 조회
- Tag Analysis: 해당 게시글들의 해시태그를 분석하여 상위 태그 추출
- Hybrid Recommendation:
- 추출된 태그 기반의 게시글 조회 (Personalized)
- 부족한 수량만큼 인기 게시글(좋아요/최신순) 조회 (Popularity)
- 두 리스트 병합 및 중복 제거 후 반환
1-2. 성능 측정 (Baseline)
Apache Bench(ab)를 사용하여 부하 테스트를 진행했습니다.
테스트 데이터는 10,000개를 넣고 진행하였습니다.
- Total Requests: 500
- Concurrency: 50
| Metric | 결과값 | |
|---|---|---|
| RPS (Throughput) | 30.19 [#/sec] | |
| Time per request | 1656[ms] |
Apache Bench 는 부하테스트에 사용하는 간단한 툴로서
짧은 시간 동안, 정해진 횟수/동시 접속 수로 HTTP 요청을 보내고, 응답 속도와 처리량을 측정해주는 도구입니다.
간단하게 작동중인 서버에 아래와 같이 요청을 보내면 부하테스트 결과를 확인할 수 있습니다.
ab -n 100 -c 10 http://localhost:8080/
-n 100 : 총 100번 요청 보내라 (requests)
-c 10 : 동시에 10명씩 붙는 것처럼(concurrent) 요청 보내라
뒤 URL : 벤치마크할 주소
아래는 실제 요청을 보내고 결과를 응답받은 예시입니다.
- 초당 처리 요청 수(Throughput, Requests per second)
- 평균 응답 시간 / 최솟값 / 최댓값
- 퍼센타일(50%, 90%, 95%, 99% 지점 응답 시간)
- 전송된 데이터량, 에러 수
를 확인 할 수 있습니다.
ab -n 500 -c 50 \
-H 'accept: */*' \
-H 'Authorization: Bearer (Access Token)' \
'https://dh.porogramr.site/api/posts/recommendPosts?limit=10'
This is ApacheBench, Version 2.3 <$Revision: 1913912 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking dh.porogramr.site (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Finished 500 requests
Server Software:
Server Hostname: dh.porogramr.site
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-CHACHA20-POLY1305,4096,256
Server Temp Key: ECDH X25519 253 bits
TLS Server Name: dh.porogramr.site
Document Path: /api/posts/recommendPosts?limit=10
Document Length: 8636 bytes
Concurrency Level: 50
Time taken for tests: 79.725 seconds
Complete requests: 500
Failed requests: 499
(Connect: 0, Receive: 0, Length: 499, Exceptions: 0)
Total transferred: 4523637 bytes
HTML transferred: 4394637 bytes
Requests per second: 6.27 [#/sec] (mean)
Time per request: 7972.543 [ms] (mean)
Time per request: 159.451 [ms] (mean, across all concurrent requests)
Transfer rate: 55.41 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 77 270 366.9 135 3122
Processing: 687 7319 3109.6 7163 19024
Waiting: 681 7305 3106.0 7148 18875
Total: 793 7588 3100.8 7368 20089
Percentage of the requests served within a certain time (ms)
50% 7368
66% 8255
75% 9444
80% 10052
90% 11284
95% 13551
98% 16034
99% 17632
100% 20089 (longest request)
2. 가설 및 검증 과정 (Troubleshooting)
Phase 1. DB 커넥션 풀(HikariCP)이 원인일까?
초기 로그 분석 결과, DB 커넥션을 획득하기 위해 스레드들이 대기하는 현상이 관측되었습니다. HikariCP의 기본 설정(Size=10)이 동시 요청 50개를 처리하기엔 턱없이 부족하다고 판단했습니다.

기본 설정 값인 10개의 커넥션이 모두 사용되고 있음을 확인할 수 있었습니다.
Action:
maximum-pool-size를 10개에서 30개로 증설했습니다.
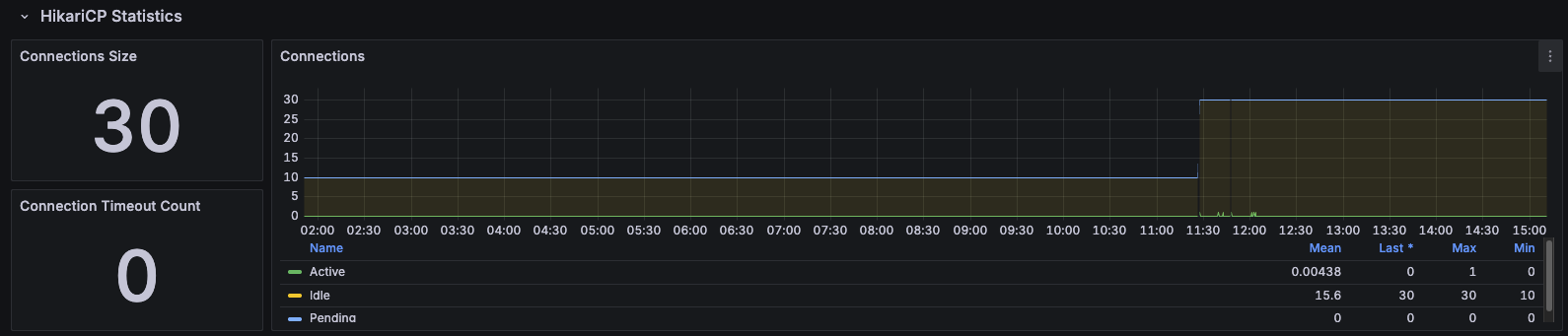
Result:
커넥션 풀을 증가시키고 Apache Bench(ab)를 사용하여 동일한 부하테스트를 진행하였습니다.
- Connection Time: 954ms → 317ms (대기 시간 감소)
- Processing Time: 639ms → 1435ms (처리 시간 2배 증가)
- RPS: 30.19 → 27.58 (오히려 성능 하락)
커넥션 풀을 늘리자 대기하던 요청들이 한꺼번에 DB로 유입되었습니다. 하지만 DB가 이를 처리하지 못해 Processing Time이 오히려 급증했습니다.
이는 "커넥션 부족은 현상일 뿐, 근본 원인은 쿼리 처리 속도(Slow Query)에 있다"는 것을 확인할 수 있었습니다.
병목 지점은 WAS가 아닌 Database 자체였습니다.
Phase 2. 쿼리 분석 및 인덱스 튜닝 (Core Solution)
DB 처리가 느린 원인을 찾기 위해 쿼리 실행 계획(Explain)과 Hibernate 로그를 분석했습니다.
두 가지 치명적인 문제가 발견되었습니다.
2-1. 비효율적인 정렬 로직 (Filesort)
기존 코드는 Post와 PostLike를 조인한 뒤, COUNT()를 사용하여 실시간으로 좋아요 개수를 세고 정렬했습니다.
[Before]
// GROUP BY와 집계 함수 사용으로 인한 성능 저하
@Query("SELECT p.postId FROM Post p LEFT JOIN p.postLikes pl GROUP BY p.postId ORDER BY COUNT(pl.id) DESC")이 쿼리는 매 요청마다 Using temporary; Using filesort를 유발하여 디스크 I/O를 폭증시켰습니다.
[After] 반정규화 및 쿼리 단순화
Post 엔티티에 likeCount 컬럼을 추가하여 반정규화를 진행했습니다. 조회 시에는 조인 없이 단일 테이블 조회로 변경했습니다.
// 이미 집계된 컬럼을 사용하여 정렬 단순화
@Query("SELECT p.postId FROM Post p ORDER BY p.likeCount DESC, p.createdAt DESC")2-2. 인덱스(Index) 부재
단순화된 쿼리라도 데이터가 많아지면 Full Table Scan이 발생합니다. EXPLAIN 확인 결과, 정렬 조건(likeCount, createdAt)에 대한 인덱스가 없어 비효율적인 스캔이 발생하고 있었습니다.
Action:
복합 인덱스를 적용하여 정렬 연산(Sorting)을 인덱스 스캔으로 대체했습니다.
1.인기 게시물 조회를 위한 인덱스 (likeCount + createdAt)
CREATE INDEX idx_post_like_count ON post (like_count DESC, created_at DESC);
2. 최신 게시물 조회를 위한 인덱스 (createdAt)
CREATE INDEX idx_post_created_at ON post (created_at DESC);
3. 사용자가 좋아한 게시물 기반 추천을 위한 인덱스
CREATE INDEX idx_post_like_user_id ON post_like (user_id);인덱싱 적용전



인덱싱 적용 후
- 다들 Type이 index로 변경된 점을 확인할 수 있다.



- key 가 변경된 모습을 확인할 수 있다.
Result (Phase 2):
- RPS: 27.58 → 42.42 (약 53% 향상)
- Processing Time: 1435ms → 334ms (약 76% 감소)
가장 큰 병목이었던 DB 처리 시간이 획기적으로 줄어들었습니다.
Phase 3. JVM 및 GC 튜닝 (Optimization)
DB 튜닝 후 RPS는 개선되었으나, 간헐적으로 응답이 튀는 현상(Tail Latency)이 있었습니다. 프로파일링 결과 GC(Garbage Collection) 수행 시 Stop-the-world가 길게 발생하는 것을 확인했습니다.

현상:
- Docker 컨테이너 환경에서 메모리 제한 설정 미비로 Host OS의 메모리를 잘못 인식
- Heap 영역 부족으로 빈번한 GC 발생 (Pause Time: ~3.47s)
Action:
- 메모리 가시성 확보:
-Xms1536, -Xmx1536m설정으로 컨테이너 메모리 제한 인식 - GC 알고리즘 변경: Latency에 유리한 ZGC (
-XX:+UseZGC) 적용 테스트

DockerFile에서 메모리 옵션, GC 튜닝 옵션 추가

GithubAction workflow 에서 메모리 제한 옵션 추가
Result:

튜닝 이후에는 부하테스트를 진행해도 GC Stop the World가 발생하지 않음
DB 튜닝으로 객체의 생존 주기가 짧아지면서 이미 G1GC로도 충분히 안정적인 상태가 되었지만, 메모리 설정을 명확히 함으로써 시스템 안정성을 확보했습니다. 최종적으로 GC로 인한 중단 시간은 0초에 수렴했습니다.
3. 최종 결과
세 단계의 튜닝을 거친 후의 성능 변화 그래프입니다.
| 단계 | RPS (req/sec) | Time per request (ms) | 비고 |
|---|---|---|---|
| Baseline | 30.19 | 1,656 | 초기 상태 |
| 1. Pool 증설 | 27.58 | 1,812 | 커넥션 대기 해소, DB 부하 증가 |
| 2. 쿼리/인덱스 | 42.42 | 1,178 | Slow Query 해결 (Key Factor) |
Lessons Learned
- 병목의 위치를 정확히 파악하라:
단순히 Connection Timeout 로그만 보고 Pool Size를 늘리는 것은 미봉책에 불과했습니다.Wait Time과Processing Time을 구분하여 분석함으로써 진짜 문제(Slow Query)를 찾을 수 있었습니다. - RDB에서 인덱스는 선택이 아닌 필수다:
복잡한 비즈니스 로직을 코드로 풀기보다, DB 레벨에서 인덱스를 잘 타도록 쿼리를 설계하는 것이 성능에 훨씬 지대한 영향을 미칩니다. - 데이터 기반의 의사결정:
ab테스트와 프로파일링 도구의 수치를 근거로 튜닝 전후를 명확히 비교할 수 있었습니다.

참고: 본 포스팅의 테스트는 로컬 Docker 환경에서 진행되었으며, 실제 운영 환경과는 차이가 있을 수 있습니다.
'JAVA' 카테고리의 다른 글
| 가상 메모리와 JVM 메모리 (0) | 2025.03.19 |
|---|---|
| 이클립스와 깃허브 연동하기 (0) | 2023.02.19 |
| Map (0) | 2023.02.14 |
| 객체 (0) | 2023.02.12 |